



Germany
Prior to releasing its AI strategy, which will be published at the Digital Summit 2018 in Nuremberg (December 3–4), Germany’s federal cabinet released a paper in July 2018 that outlines the goals of the strategy. In short, the government wants to strengthen and expand German and European research in AI and focus on the transfer of research results to the private sector and the creation of AI applications. Proposed initiatives to achieve this include new research centres, Franco-Germany research and development collaboration, regional cluster funding, and support for SMEs and start-ups. The proposed plan is quite comprehensive and also includes measures to attract international talent, respond to the changing nature of work, integrate AI into government services, make public data more accessible, and promote the development of transparent and ethical AI. Overall, the government wants “AI made in Germany” to become a globally recognized seal of quality.
In addition to its forthcoming strategy, Germany already has a number of related policies in place to develop AI. Principally, the government, in partnership with academia and industry actors, focuses on integrating AI technologies into Germany’s export sectors. The flagship program has been Industry 4.0, but recently the strategic goal has shifted to smart services, which relies more on AI technologies. The German Research Centre for AI (DFKI) is a major actor in this pursuit and provides funding for application oriented research. Other relevant organizations include the Alexander von Humboldt Foundation, which promotes academic cooperation and attracts scientific talent to work in Germany, and the Plattform Lernende Systeme, which brings together experts from science, industry, politics, and civic organizations to develop practical recommendations for the government. The government has also announced a new commission to investigate how AI and algorithmic decision-making will affect society. It consists of 19 MPs and 19 AI experts and is tasked with developing a report with recommendations by 2020 (a similar task force released a report on the ethics of autonomous vehicles in June 2017).
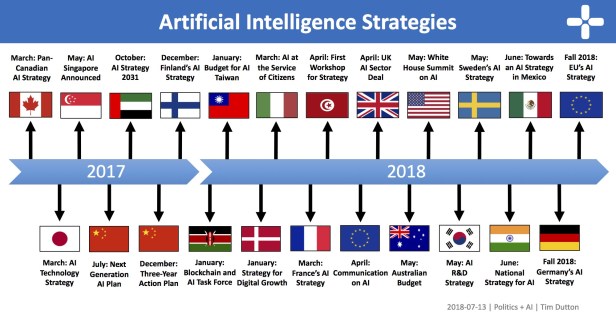
More: Overview about National AI Strategies
Artificial Intelligence -From Science Fiction to Science Progress
What is Artificial intelligence ?
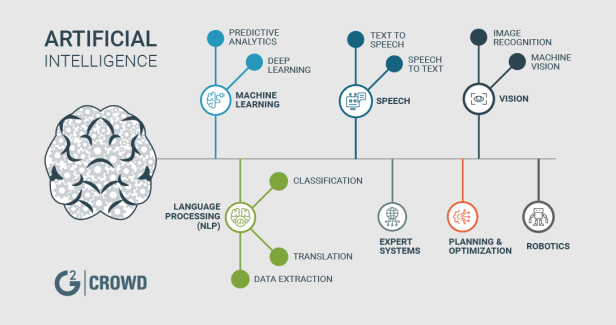
What is Artificial Intelligence
In computer science, artificial intelligence (AI), sometimes called machine intelligence, is intelligence demonstrated by machines, in contrast to the natural intelligence displayed by humans and other animals. Computer science defines AI research as the study of “intelligent agents”: any device that perceives its environment and takes actions that maximize its chance of successfully achieving its goals.[1] More in detail, Kaplan and Haenlein define AI as “a system’s ability to correctly interpret external data, to learn from such data, and to use those learnings to achieve specific goals and tasks through flexible adaptation”.[2] Colloquially, the term “artificial intelligence” is applied when a machine mimics “cognitive” functions that humans associate with other human minds, such as “learning” and “problem solving”.[3]
In Summary, Artificial intelligence (AI) is an area of computer science that emphasizes the creation of intelligent machines that work and react like humans. Some of the activities computers with artificial intelligence are designed for include:
-Speech recognition
-Learning
-Planning
-Problem solving
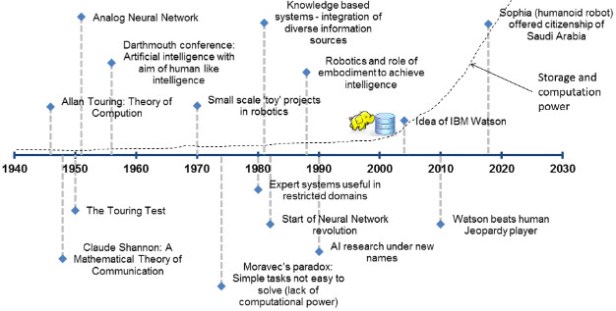
Timelines of Artificial Intelligence (AI)
From Wikipedia, the free encyclopedia


Sutori
Forbes
IBM Business Partner Network
Coho Productions & IBM
My Artificial Intelligence Timeline 1980 until now


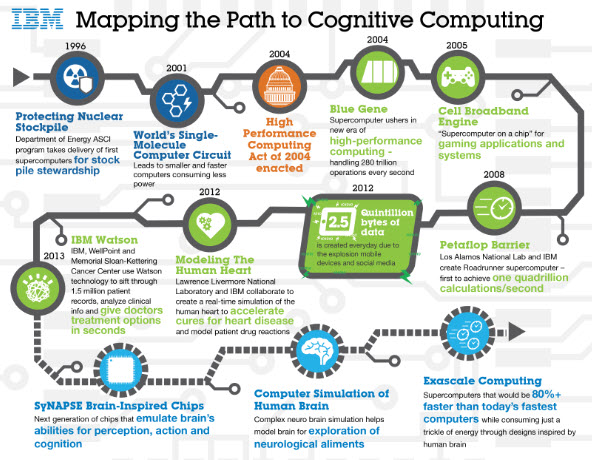
I first get in touch with Artificial Intelligence in 1980. At this time, the AI science focus was on Knowledge-based/Expert Systems. These computer programs in Prolog/Turbo Prolog are based on the idea that you can use rules to encode all human knowledge in Expert Systems. During my time as Manager Marketing Database at Citicorp Credit Card Services (1990-1994) I get in touch with Neural Networks. At Citicorp Neural Networks have been/are used to analyse and define Fraud Detection and Creditlines by types of Credit Card holders.
When I worked as CRM & BI Program Director at Deutsche Leasing AG, S-Finance Group (1994-2008) we used Neural Networks to analyze good and bad Leasing Clients and to Forecast CRM Activities. When I worked as Business Development Manager/Software Client Leader and IBM Watson Ambassador at IBM (2008-2015), I get in touch with IBM Watson and Reinforcement Learning.
That moment came in 2013, when IBM Watson, trained with reinforcement learning and defeated Humans in Jeopardy. The effect on the research community was immediate.

IBM is installing a Watson AI lab at MIT
Both MIT and IBM are leaders in the field of Artificial Intelligence and now they’re teaming up. IBM announced on Thursday that it had reached a 10-year research partnership agreement with the university worth nearly a quarter of a billion dollars. That investment will see more than 100 researchers from both organizations collaborating to advance four key focus areas within the AI field.
Those focal areas include deep-learning algorithms that can help neural networks move from single-use applications to more generalized performance. Not only will this make AI systems more versatile, it will improve their transparency as well, enabling them to explain how they reached the answer they did.
The IBM-MIT partnership will also study the intersection between machine learning and quantum computing. Interestingly, this focal area will aid both fields, with AI helping to identify and characterize quantum devices and with quantum computers helping to optimize machine learning methodologies.
The MIT lab will also collaborate extensively with the IBM Watson Healthand Security office in nearby Cambridge, Massachusetts, to further develop applications in the existing AI healthcare and cybersecurity fields. But those aren’t the only commercial fields being investigated, researchers will also look into the “economic implications of AI and investigate how AI can improve prosperity,” according to an IBM press release.
This isn’t the first time that these organizations have worked together. Just last year, IBM and the MIT Department of Brain and Cognitive Sciences began orchestrating a machine vision study. What’s more, IBM has also teamed with MIT’s Broad Institute and Harvard for a multi-year study of AI’s effects on Genomics.
Our study of 25 years of artificial-intelligence research suggests the era of deep learning is coming to an end. by Karen Hao, January 25, 2019
Among the top 100 words mentioned in the 1980s, are those related to knowledge-based systems—like “logic,” “constraint,” and “rule”—saw the greatest decline. Those related to machine learning—like “data,” “network,” and “performance”—saw the highest growth.
The reason for this sea change is rather simple. In the ’80s, knowledge-based systems amassed a popular following thanks to the excitement surrounding ambitious projects that were attempting to re-create common sense within machines. But as those projects unfolded, researchers hit a major problem: there were simply too many rules that needed to be encoded for a system to do anything useful. This jacked up costs and significantly slowed ongoing efforts.
Machine learning became an answer to that problem. Instead of requiring people to manually encode hundreds of thousands of rules, this approach programs machines to extract those rules automatically from a pile of data. Just like that, the field abandoned knowledge-based systems and turned to refining machine learning.
THE NEURAL-NETWORK BOOM
Under the new machine-learning paradigm, the shift to deep learning didn’t happen immediately. Instead, as our analysis of key terms shows, researchers tested a variety of methods in addition to neural networks, the core machinery of deep learning. Some of the other popular techniques included Bayesian networks, support vector machines, and evolutionary algorithms, all of which take different approaches to finding patterns in data.
Through the 1990s and 2000s, there was steady competition between all of these methods. Then, in 2012, a pivotal breakthrough led to another sea change. During the annual ImageNet competition, intended to spur progress in computer vision, a researcher named Geoffrey Hinton, along with his colleagues at the University of Toronto, achieved the best accuracy in image recognition by an astonishing margin of more than 10 percentage points.
The technique he used, deep learning, sparked a wave of new research—first within the vision community and then beyond. As more and more researchers began using it to achieve impressive results, its popularity—along with that of neural networks—exploded.
THE RISE OF REINFORCEMENT LEARNING
In the few years since the rise of deep learning, our analysis reveals, a third and final shift has taken place in AI research.
As well as the different techniques in machine learning, there are three different types: supervised, unsupervised, and reinforcement learning. Supervised learning, which involves feeding a machine labeled data, is the most commonly used and also has the most practical applications by far. In the last few years, however, reinforcement learning, which mimics the process of training animals through punishments and rewards, has seen a rapid uptick of mentions in paper abstracts.
The idea isn’t new, but for many decades it didn’t really work. “The supervised-learning people would make fun of the reinforcement-learning people,” Domingos says. But, just as with deep learning, one pivotal moment suddenly placed it on the map.
That moment came in October 2015, when DeepMind’s AlphaGo, trained with reinforcement learning, defeated the world champion in the ancient game of Go. The effect on the research community was immediate.
THE NEXT DECADE
Our analysis provides only the most recent snapshot of the competition among ideas that characterizes AI research. But it illustrates the fickleness of the quest to duplicate intelligence. “The key thing to realize is that nobody knows how to solve this problem,” Domingos says.
Many of the techniques used in the last 25 years originated at around the same time, in the 1950s, and have fallen in and out of favor with the challenges and successes of each decade. Neural networks, for example, peaked in the ’60s and briefly in the ’80s but nearly died before regaining their current popularity through deep learning.
Every decade, in other words, has essentially seen the reign of a different technique: neural networks in the late ’50s and ’60s, various symbolic approaches in the ’70s, knowledge-based systems in the ’80s, Bayesian networks in the ’90s, support vector machines in the ’00s, and neural networks again in the ’10s.
The 2020s should be no different, says Domingos, meaning the era of deep learning may soon come to an end. But characteristically, the research community has competing ideas about what will come next—whether an older technique will regain favor or whether the field will create an entirely new paradigm.
“If you answer that question,” Domingos says, “I want to patent the answer.”
More:
34. The road to Artificial Super Intelligence (ASI) and Artificial Virtual Assistants (AVA)
